|
|
@@ -6,6 +6,9 @@ The :ref:`first-steps` guide is intentionally minimal. In this guide
|
|
|
we will demonstrate what Celery offers in more detail, including
|
|
|
how to add Celery support for your application and library.
|
|
|
|
|
|
+.. contents::
|
|
|
+ :local:
|
|
|
+
|
|
|
|
|
|
Our Project
|
|
|
===========
|
|
|
@@ -17,38 +20,218 @@ Project layout::
|
|
|
/tasks.py
|
|
|
|
|
|
:file:`proj/celery.py`
|
|
|
+----------------------
|
|
|
|
|
|
.. literalinclude:: ../../examples/next-steps/proj/celery.py
|
|
|
- :language python:
|
|
|
+ :language: python
|
|
|
+
|
|
|
+In this module we created our :class:`@Celery` instance. This is something
|
|
|
+referred to as the celery *app*. Your project
|
|
|
+imports celery from this module to access Celery's features.
|
|
|
+It's possible to use several app instances at once, but that
|
|
|
+will not be covered in this tutorial.
|
|
|
+
|
|
|
+- The ``broker`` argument specifies the URL of the broker to use.
|
|
|
+
|
|
|
+ See :ref:`celerytut-broker` for more information.
|
|
|
+
|
|
|
+- The ``backend`` argument specifies the result backend to use,
|
|
|
|
|
|
+ It's used to keep track of task state and results.
|
|
|
+ While results are disabled by default we use the amqp backend here
|
|
|
+ to demonstrate how retrieving the results work, you may want to use
|
|
|
+ a different backend for your application, as they all have different
|
|
|
+ strenghts and weaknesses. If you don't need results it's best
|
|
|
+ to disable them. Results can also be disabled for individual tasks
|
|
|
+ by setting the ``@task(ignore_result=True)`` option.
|
|
|
+
|
|
|
+ See :ref:`celerytut-keeping-results` for more information.
|
|
|
+
|
|
|
+- The ``include`` argument is a list of modules to import when
|
|
|
+ the worker starts. We need to add our tasks module here so
|
|
|
+ that the worker is able to find our tasks.
|
|
|
|
|
|
:file:`proj/tasks.py`
|
|
|
+---------------------
|
|
|
|
|
|
.. literalinclude:: ../../examples/next-steps/proj/tasks.py
|
|
|
- :language python:
|
|
|
+ :language: python
|
|
|
+
|
|
|
+
|
|
|
+Starting the worker
|
|
|
+===================
|
|
|
|
|
|
+The :program:`celery` program can be used to start the worker::
|
|
|
+
|
|
|
+ $ celery worker --app=proj -l info
|
|
|
+
|
|
|
+The :option:`--app` argument specifies the Celery app instance to use,
|
|
|
+it must be in the form of ``module.path:celery``, where the part before the colon
|
|
|
+is the name of the module, and the attribute name comes last.
|
|
|
+If a package name is specified instead it will automatically
|
|
|
+try to find a ``celery`` module in that package, and if the name
|
|
|
+is a module it will try to find a ``celery`` attribute in that module.
|
|
|
+This means that the following all results in the same::
|
|
|
+
|
|
|
+ $ celery --app=proj
|
|
|
+ $ celery --app=proj.celery:
|
|
|
+ $ celery --app=proj.celery:celery
|
|
|
|
|
|
|
|
|
Subtasks
|
|
|
========
|
|
|
|
|
|
+A :func:`~celery.subtask` wraps the signature of a single task invocation:
|
|
|
+arguments, keyword arguments and execution options.
|
|
|
|
|
|
-group
|
|
|
------
|
|
|
+A subtask for the ``add`` task can be created like this::
|
|
|
|
|
|
-.. code-block:: python
|
|
|
+ >>> from celery import subtask
|
|
|
+ >>> subtask(add.name, args=(4, 4))
|
|
|
+
|
|
|
+or you can create one from the task itself::
|
|
|
+
|
|
|
+ >>> from proj.tasks import add
|
|
|
+ >>> add.subtask(args=(4, 4))
|
|
|
+
|
|
|
+It takes the same arguments as the :meth:`~@Task.apply_async` method::
|
|
|
+
|
|
|
+ >>> add.apply_async(args, kwargs, **options)
|
|
|
+ >>> add.subtask(args, kwargs, **options)
|
|
|
+
|
|
|
+ >>> add.apply_async((2, 2), countdown=1)
|
|
|
+ >>> add.subtask((2, 2), countdown=1)
|
|
|
+
|
|
|
+And like there is a :meth:`~@Task.delay` shortcut for `apply_async`
|
|
|
+there is a :meth:`~@Task.s` shortcut for subtask::
|
|
|
+
|
|
|
+ >>> add.s(*args, **kwargs)
|
|
|
+
|
|
|
+ >>> add.s(2, 2)
|
|
|
+ proj.tasks.add(2, 2)
|
|
|
+
|
|
|
+ >>> add.s(2, 2) == add.subtask((2, 2))
|
|
|
+ True
|
|
|
+
|
|
|
+You can't define options with :meth:`~@Task.s`, but a chaining
|
|
|
+``set`` call takes care of that::
|
|
|
+
|
|
|
+ >>> add.s(2, 2).set(countdown=1)
|
|
|
+ proj.tasks.add(2, 2)
|
|
|
+
|
|
|
+Partials
|
|
|
+--------
|
|
|
+
|
|
|
+A subtask can be applied too::
|
|
|
+
|
|
|
+ >>> add.s(2, 2).delay()
|
|
|
+ >>> add.s(2, 2).apply_async(countdown=1)
|
|
|
+
|
|
|
+Specifying additional args, kwargs or options to ``apply_async``/``delay``
|
|
|
+creates partials:
|
|
|
+
|
|
|
+- Any arguments added will be prepended to the args in the signature::
|
|
|
+
|
|
|
+ >>> partial = add.s(2) # incomplete signature
|
|
|
+ >>> partial.delay(4) # 2 + 4
|
|
|
+ >>> partial.apply_async((4, )) # same
|
|
|
+
|
|
|
+- Any keyword arguments added will be merged with the kwargs in the signature,
|
|
|
+ with the new keyword arguments taking precedence::
|
|
|
+
|
|
|
+ >>> s = add.s(2, 2)
|
|
|
+ >>> s.delay(debug=True) # -> add(2, 2, debug=True)
|
|
|
+ >>> s.apply_async(kwargs={"debug": True}) # same
|
|
|
+
|
|
|
+- Any options added will be merged with the options in the signature,
|
|
|
+ with the new options taking precedence::
|
|
|
+
|
|
|
+ >>> s = add.subtask((2, 2), countdown=10)
|
|
|
+ >>> s.apply_async(countdown=1) # countdown is now 1
|
|
|
+
|
|
|
+You can also clone subtasks to augment these::
|
|
|
+
|
|
|
+ >>> s = add.s(2)
|
|
|
+ proj.tasks.add(2)
|
|
|
+
|
|
|
+ >>> s.clone(args=(4, ), kwargs={"debug": True})
|
|
|
+ proj.tasks.add(2, 4, debug=True)
|
|
|
+
|
|
|
+Partials are meant to be used with callbacks, any tasks linked or chord
|
|
|
+callbacks will be applied with the result of the parent task.
|
|
|
+Sometimes you want to specify a callback that does not take
|
|
|
+additional arguments, and in that case you can set the subtask
|
|
|
+to be immutable::
|
|
|
+
|
|
|
+ >>> add.s(2, 2).link( reset_buffers.subtask(immutable=True) )
|
|
|
+
|
|
|
+Only the execution options can be set when a subtask is immutable,
|
|
|
+and it's not possible to apply the subtask with partial args/kwargs.
|
|
|
+
|
|
|
+.. note::
|
|
|
+
|
|
|
+ In this tutorial we use the prefix operator `~` to subtasks.
|
|
|
+ You probably shouldn't use it in your production code, but it's a handy shortcut
|
|
|
+ when testing with the Python shell::
|
|
|
+
|
|
|
+ >>> ~subtask
|
|
|
+
|
|
|
+ >>> # is the same as
|
|
|
+ >>> subtask.delay().get()
|
|
|
+
|
|
|
+Groups
|
|
|
+------
|
|
|
+
|
|
|
+A group can be used to execute several tasks in parallel.
|
|
|
+
|
|
|
+The :class:`~celery.group` function takes a list of subtasks::
|
|
|
|
|
|
>>> from celery import group
|
|
|
>>> from proj.tasks import add
|
|
|
|
|
|
- >>> ~group(add.s(i, i) for i in xrange(10))
|
|
|
- [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
|
|
|
+ >>> group(add.s(2, 2), add.s(4, 4))
|
|
|
+ (proj.tasks.add(2, 2), proj.tasks.add(4, 4))
|
|
|
+
|
|
|
+If you **call** the group, the tasks will be applied
|
|
|
+one after one in the current process, and a :class:`~@TaskSetResult`
|
|
|
+instance is returned which can be used to keep track of the results,
|
|
|
+or tell how many tasks are ready and so on::
|
|
|
+
|
|
|
+ >>> g = group(add.s(2, 2), add.s(4, 4))
|
|
|
+ >>> res = g()
|
|
|
+ >>> res.get()
|
|
|
+ [4, 8]
|
|
|
|
|
|
- >>> group(add.s(i, i) for i in xrange(10)).skew(1, 10)
|
|
|
+However, if you call ``apply_async`` on the group it will
|
|
|
+send a special grouping task, so that the action of applying
|
|
|
+the tasks happens in a worker instead of the current process::
|
|
|
|
|
|
-map/starmap
|
|
|
+ >>> res = g.apply_async()
|
|
|
+ >>> res.get()
|
|
|
+ [4, 8]
|
|
|
+
|
|
|
+Group also supports iterators::
|
|
|
+
|
|
|
+ >>> group(add.s(i, i) for i in xrange(100))()
|
|
|
+
|
|
|
+
|
|
|
+A group is a subclass instance, so it can be used in combination
|
|
|
+with other subtasks.
|
|
|
+
|
|
|
+Map & Starmap
|
|
|
-------------
|
|
|
|
|
|
+:class:`~celery.map` and :class:`~celery.starmap` are built-in tasks
|
|
|
+that calls the task for every element in a sequence.
|
|
|
+
|
|
|
+They differ from group in that
|
|
|
+
|
|
|
+- only one task message is sent
|
|
|
+
|
|
|
+- the operation is sequential.
|
|
|
+
|
|
|
+For example using ``map``:
|
|
|
+
|
|
|
.. code-block:: python
|
|
|
|
|
|
>>> from proj.tasks import add
|
|
|
@@ -56,19 +239,233 @@ map/starmap
|
|
|
>>> ~xsum.map([range(10), range(100)])
|
|
|
[45, 4950]
|
|
|
|
|
|
+is the same as having a task doing:
|
|
|
+
|
|
|
+.. code-block:: python
|
|
|
+
|
|
|
+ @celery.task
|
|
|
+ def temp():
|
|
|
+ return [xsum(range(10)), xsum(range(100))]
|
|
|
+
|
|
|
+and using ``starmap``::
|
|
|
+
|
|
|
>>> ~add.starmap(zip(range(10), range(10)))
|
|
|
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
|
|
|
|
|
|
+is the same as having a task doing:
|
|
|
+
|
|
|
+.. code-block:: python
|
|
|
+
|
|
|
+ @celery.task
|
|
|
+ def temp():
|
|
|
+ return [add(i, i) for i in range(10)]
|
|
|
+
|
|
|
+Both ``map`` and ``starmap`` are subtasks, so they can be used as
|
|
|
+other subtasks and combined in groups etc., for example
|
|
|
+to apply the starmap after 10 seconds::
|
|
|
+
|
|
|
>>> add.starmap(zip(range(10), range(10))).apply_async(countdown=10)
|
|
|
|
|
|
-chunks
|
|
|
-------
|
|
|
+Chunking
|
|
|
+--------
|
|
|
+
|
|
|
+-- Chunking lets you divide a iterable of work into pieces,
|
|
|
+ so that if you have one million objects, you can create
|
|
|
+ 10 tasks with hundred thousand objects each.
|
|
|
+
|
|
|
+Some may worry that chunking your tasks results in a degradation
|
|
|
+of parallelism, but this is rarely true for a busy cluster
|
|
|
+and in practice since you are avoiding the overhead of messaging
|
|
|
+it may considerably increase performance.
|
|
|
+
|
|
|
+To create a chunks subtask you can use :meth:`@Task.chunks`:
|
|
|
+
|
|
|
+.. code-block:: python
|
|
|
+
|
|
|
+ >>> add.chunks(zip(range(100), range(100)), 10)
|
|
|
+
|
|
|
+As with :class:`~celery.group` the act of **calling**
|
|
|
+the chunks will apply the tasks in the current process:
|
|
|
|
|
|
.. code-block:: python
|
|
|
|
|
|
>>> from proj.tasks import add
|
|
|
|
|
|
- >>> ~add.chunks(zip(range(100), range(100)), 10)
|
|
|
+ >>> res = add.chunks(zip(range(100), range(100)), 10)()
|
|
|
+ >>> res.get()
|
|
|
+ [[0, 2, 4, 6, 8, 10, 12, 14, 16, 18],
|
|
|
+ [20, 22, 24, 26, 28, 30, 32, 34, 36, 38],
|
|
|
+ [40, 42, 44, 46, 48, 50, 52, 54, 56, 58],
|
|
|
+ [60, 62, 64, 66, 68, 70, 72, 74, 76, 78],
|
|
|
+ [80, 82, 84, 86, 88, 90, 92, 94, 96, 98],
|
|
|
+ [100, 102, 104, 106, 108, 110, 112, 114, 116, 118],
|
|
|
+ [120, 122, 124, 126, 128, 130, 132, 134, 136, 138],
|
|
|
+ [140, 142, 144, 146, 148, 150, 152, 154, 156, 158],
|
|
|
+ [160, 162, 164, 166, 168, 170, 172, 174, 176, 178],
|
|
|
+ [180, 182, 184, 186, 188, 190, 192, 194, 196, 198]]
|
|
|
+
|
|
|
+while calling ``.apply_async`` will create a dedicated
|
|
|
+task so that the individual tasks are applied in a worker
|
|
|
+instead::
|
|
|
+
|
|
|
+ >>> add.chunks(zip(range(100), range(100), 10)).apply_async()
|
|
|
+
|
|
|
+You can also convert chunks to a group::
|
|
|
+
|
|
|
+ >>> group = add.chunks(zip(range(100), range(100), 10)).group()
|
|
|
+
|
|
|
+and with the group skew the countdown of each task by increments
|
|
|
+of one::
|
|
|
+
|
|
|
+ >>> group.skew(start=1, stop=10)()
|
|
|
+
|
|
|
+which means that the first task will have a countdown of 1, the second
|
|
|
+a countdown of 2 and so on.
|
|
|
|
|
|
|
|
|
+Chaining tasks
|
|
|
+--------------
|
|
|
|
|
|
+Tasks can be linked together, which in practice means adding
|
|
|
+a callback task::
|
|
|
+
|
|
|
+ >>> res = add.apply_async((2, 2), link=mul.s(16))
|
|
|
+ >>> res.get()
|
|
|
+ 4
|
|
|
+
|
|
|
+The linked task will be applied with the result of its parent
|
|
|
+task as the first argument, which in the above case will result
|
|
|
+in ``mul(4, 16)`` since the result is 4.
|
|
|
+
|
|
|
+The results will keep track of what subtasks a task applies,
|
|
|
+and this can be accessed from the result instance::
|
|
|
+
|
|
|
+ >>> res.children
|
|
|
+ [<AsyncResult: 8c350acf-519d-4553-8a53-4ad3a5c5aeb4>]
|
|
|
+
|
|
|
+ >>> res.children[0].get()
|
|
|
+ 64
|
|
|
+
|
|
|
+The result instance also has a :meth:`~@AsyncResult.collect` method
|
|
|
+that treats the result as a graph, enabling you to iterate over
|
|
|
+the results::
|
|
|
+
|
|
|
+ >>> list(res.collect())
|
|
|
+ [(<AsyncResult: 7b720856-dc5f-4415-9134-5c89def5664e>, 4),
|
|
|
+ (<AsyncResult: 8c350acf-519d-4553-8a53-4ad3a5c5aeb4>, 64)]
|
|
|
+
|
|
|
+By default :meth:`~@AsyncResult.collect` will raise an
|
|
|
+:exc:`~@IncompleteStream` exception if the graph is not fully
|
|
|
+formed (one of the tasks has not completed yet),
|
|
|
+but you can get an intermediate representation of the graph
|
|
|
+too::
|
|
|
+
|
|
|
+ >>> for result, value in res.collect(intermediate=True)):
|
|
|
+ ....
|
|
|
+
|
|
|
+You can link together as many tasks as you like,
|
|
|
+and subtasks can be linked too::
|
|
|
+
|
|
|
+ >>> s = add.s(2, 2)
|
|
|
+ >>> s.link(mul.s(4))
|
|
|
+ >>> s.link(log_result.s())
|
|
|
+
|
|
|
+You can also add *error callbacks* using the ``link_error`` argument::
|
|
|
+
|
|
|
+ >>> add.apply_async((2, 2), link_error=log_error.s())
|
|
|
+
|
|
|
+ >>> add.subtask((2, 2), link_error=log_error.s())
|
|
|
+
|
|
|
+Since exceptions can only be serialized when pickle is used
|
|
|
+the error callbacks take the id of the parent task as argument instead:
|
|
|
+
|
|
|
+.. code-block:: python
|
|
|
+
|
|
|
+ from proj.celery import celery
|
|
|
+
|
|
|
+ @celery.task
|
|
|
+ def log_error(task_id):
|
|
|
+ result = celery.AsyncResult(task_id)
|
|
|
+ result.get(propagate=False) # make sure result written.
|
|
|
+ with open("/var/errors/%s" % (task_id, )) as fh:
|
|
|
+ fh.write("--\n\n%s %s %s" % (
|
|
|
+ task_id, result.result, result.traceback))
|
|
|
+
|
|
|
+To make it even easier to link tasks together there is
|
|
|
+a special subtask called :class:`~celery.chain` that lets
|
|
|
+you chain tasks together:
|
|
|
+
|
|
|
+.. code-block:: python
|
|
|
+
|
|
|
+ >>> from celery import chain
|
|
|
+ >>> from proj.tasks import add, mul
|
|
|
+
|
|
|
+ # (4 + 4) * 8 * 10
|
|
|
+ >>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))
|
|
|
+ proj.tasks.add(4, 4) | proj.tasks.mul(8)
|
|
|
+
|
|
|
+
|
|
|
+Calling the chain will apply the tasks in the current process
|
|
|
+and return the result of the last task in the chain::
|
|
|
+
|
|
|
+ >>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))
|
|
|
+ >>> res.get()
|
|
|
+ 640
|
|
|
+
|
|
|
+And calling ``apply_async`` will create a dedicated
|
|
|
+task so that the act of applying the chain happens
|
|
|
+in a worker::
|
|
|
+
|
|
|
+ >>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))
|
|
|
+ >>> res.get()
|
|
|
+ 640
|
|
|
+
|
|
|
+It also sets ``parent`` attributes so that you can
|
|
|
+work your way up the chain to get intermediate results::
|
|
|
+
|
|
|
+ >>> res.parent.get()
|
|
|
+ 64
|
|
|
+
|
|
|
+ >>> res.parent.parent.get()
|
|
|
+ 8
|
|
|
+
|
|
|
+ >>> res.parent.parent
|
|
|
+ <AsyncResult: eeaad925-6778-4ad1-88c8-b2a63d017933>
|
|
|
+
|
|
|
+
|
|
|
+Chains can also be made using the ``|`` (pipe) operator::
|
|
|
+
|
|
|
+ >>> (add.s(2, 2) | mul.s(8) | mul.s(10)).apply_async()
|
|
|
+
|
|
|
+Graphs
|
|
|
+~~~~~~
|
|
|
+
|
|
|
+In addition you can work with the result graph as a
|
|
|
+:class:`~celery.datastructures.DependencyGraph`:
|
|
|
+
|
|
|
+.. code-block:: python
|
|
|
+
|
|
|
+ >>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))()
|
|
|
+
|
|
|
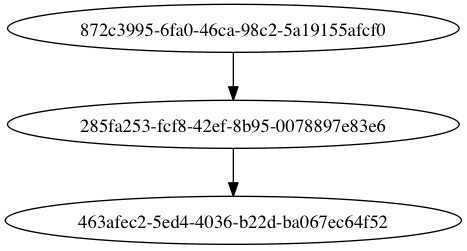
+ >>> res.parent.parent.graph
|
|
|
+ 285fa253-fcf8-42ef-8b95-0078897e83e6(1)
|
|
|
+ 463afec2-5ed4-4036-b22d-ba067ec64f52(0)
|
|
|
+ 872c3995-6fa0-46ca-98c2-5a19155afcf0(2)
|
|
|
+ 285fa253-fcf8-42ef-8b95-0078897e83e6(1)
|
|
|
+ 463afec2-5ed4-4036-b22d-ba067ec64f52(0)
|
|
|
+
|
|
|
+You can even convert these graphs to *dot* format::
|
|
|
+
|
|
|
+ >>> with open("graph.dot", "w") as fh:
|
|
|
+ ... res.parent.parent.graph.to_dot(fh)
|
|
|
+
|
|
|
+
|
|
|
+and create images::
|
|
|
+
|
|
|
+ $ dot -Tpng graph.dot -o graph.png
|
|
|
+
|
|
|
+.. image:: ../images/graph.png
|
|
|
+
|
|
|
+
|
|
|
+Chords
|
|
|
+------
|

 Ask Solem
Ask Solem
{kind=link}